クローラビリティを向上して上位表示するための改善ポイント11選




クローラビリティは、Webサイトが検索で上位表示にランクインするためにとても重要です。
しかし、具体的に何を改善すればクローラビリティが向上するのか分からない方が多いのが現状です。
『クローラビリティはSEOに関係する?』
『クローラビリティの改善方法を知りたい』
『クローラーが巡回しているか確認したい』
今回のコラム記事では、上記のような悩みがある方に向けて、クローラビリティを向上して上位表示するための改善ポイントを11選ご紹介します。
クローラビリティとは
クローラビリティとは、検索エンジンのクローラーにとって「訪れやすいWebサイト」または「クロールしやすいWebサイト」のことを指します。
そもそも、検索エンジンのクローラーは、インターネット上にあるWebサイトのリンクをたどって情報収集をしながら巡回しています(この作業をクロールといいます)。
検索エンジンのクローラーは24時間年中無休でインターネットを通してWebサイトを巡回しており、読み込まれたWebページの情報は検索エンジンのデータベースに分類・登録(インデックス)されます。
つまり、クローラビリティの向上は「インデックスされやすいWebサイト」といえます。
ただし、リンク切れ(404ページ)やWebページのクロールをブロックする設定をしていると、クローラーはWebページの情報を読み取れないのでインデックスされません。
クローラビリティとSEOの関係
一般的にSEOといえば、コンテンツやユーザーエクスペリエンスが主軸になりがちですが、クローラビリティは検索エンジン向けの技術的なSEO対策です。
クローラビリティが向上しているWebサイトは、そうでないWebサイトと比べてSEO面で有利です。
これは、検索エンジンの検索結果に表示されるWebページが関係していきます。
普段から私たちが見ている検索結果は、検索エンジンにインデックスされたWebページの中からランキング形式で表示されています。
ですので、検索エンジンのクローラーが訪問しやすくて隅々までクロールしやすいWebサイト(クローラビリティが高いWebサイト)は、インデックス登録されやすい状態です。
検索結果で上位表示を獲得するには、クローラーにWebページを訪問してもらい、インデックス登録される必要があるため、クローラビリティが高いWebサイトはSEO面で有利に働きます。
また、高品質なコンテンツのインデックス数が増し、Web上で重要度が高いWebサイトと判断されると、クローラーの訪問頻度が増えます。
つまり、クローラビリティの向上により、SEO効果を得るためには「コンテンツの品質」が大事です。
クローラビリティを向上させるために改善すべきこと11選
クローラビリティを向上させるために改善すべきこと11選は以下の通りです。
- Googleサーチコンソールでクロールをリクエスト
- XMLサイトマップの作成・設置
- 内部リンクの最適化
- 高品質なコンテンツの作成
- 被リンク(外部リンク)の獲得
- 重複ページのURLを正規化
- Webサーバーの最適化
- ファイルの最適化
- 正しいHTTPステータスコードを返す
- シンプルなURLを設定
- 特定のファイルにrobots.txtを設定
それぞれ詳しく解説していきます。
Googleサーチコンソールでクロールをリクエスト
Googleサーチコンソールでクロールのリクエストをすると、一時的にクローラビリティが向上します。
Webページを作成、更新した場合には検索エンジンのクローラーが訪問しなければ検索結果にWebページの存在や変更が反映されません。
しかし、Googleサーチコンソールの「URL検査」ツールを利用すれば、クローラーが対象となるWebページに訪問・巡回してくれるようにリクエストできます。
Googleサーチコンソールでクロールをリクエストする方法は、クローラビリティ向上の一時的なものです。
Webサイト全体的にクローラビリティの向上を長期的に目指すには、以降に解説する改善が必要となります。
XMLサイトマップの作成・設置
XMLサイトマップの作成・設置により、Webサイトのクローラビリティが向上します。
XMLサイトマップとは、Webサイト内の構造やコンテンツを検索エンジンが理解しやすいように作成・設置するファイルのことです。
XMLサイトマップはWebサイト内の構造やコンテンツ情報を1つのファイルにまとめているため、クロールの手間を大幅に省けます。
以下の条件が該当するWebサイトには、XMLサイトマップの作成・設置をおすすめします。
- Webページが多い(500ページ以上)
- 内部リンクが適正化されていない
- 外部被リンクの獲得が少ない
- クロールするコンテンツ(画像や動画)が多い
関連記事
サイトマップのSEO効果や作成方法、設置(登録)方法については、それぞれ以下のコラム記事をご覧ください。
・【サイトマップとは】SEOに効果的?設置するメリット・デメリットなど徹底解説
・XMLサイトマップの作成方法!おすすめのツール5選【完全ガイド】
・Googleサーチコンソールにサイトマップを登録する方法【エラー原因と対処方法も】
内部リンクの最適化
内部リンクの最適化を行うことで、クローラビリティが向上します。
前述したXMLサイトマップの設置・作成も内部リンクの最適化の一つです。
内部リンクには、アンカーテキスト・パンくずリスト・ナビゲーションなど、さまざまな種類があります。
クローラーは、Webサイト内の内部リンクをたどってクロールするため、内部リンクの設置はクローラビリティの向上にとても重要です。
内部リンクの設置は、Webサイトに訪問してくるユーザーの利便性を考慮し設置すると上手くいきます。
例えば、関連性のあるWebページ同士を内部リンクでつなぐことで、ユーザーは欲しい情報にたどり着きやすくなります。
ユーザビリティの向上を目指すことで、結果的に内部リンクが最適化されクローラビリティが向上するのです。
高品質なコンテンツの作成
高品質なコンテンツの作成により、クローラビリティが向上します。
コンテンツの品質はクローラビリティにとっても重要です。
ここでいう高品質なコンテンツとは、検索ユーザーに対して有益な情報を提供し、検索した目的を達成できるコンテンツ(Webページ)です。
反対に、検索ユーザーが求めている情報を提供できていない低品質なコンテンツがWebサイト上にあると、無駄なクロールが行われて結果的にクローラビリティの低下にもつながります。
ユーザーが何故そのキーワード(クエリ)で検索するのか意図を理解し、ユーザーが知りたい情報はもちろん、満足のいくコンテンツを作成や更新していく必要があります。
また、高品質なコンテンツの多いWebサイトは検索エンジンから高い評価を受けやすく、ユーザーからも人気があるはずです。
Googleでは、Web上で人気のあるURL(Webページ)は、頻繁にクロールされると述べられています。
- 検出された URL 群: Googlebot は、ユーザーの指示がなければ、サイト上の認識している URL のすべてまたはほとんどをクロールしようとします。多くの URL が重複している場合や、他の理由(削除されている、または重要でない URL など)でクロールされたくない場合、サイトのクロールに費やす時間の多くが無駄になってしまいます。これは最も確実に管理できる要素です。
- 人気度: インターネット上で人気の高い URL ほど、Google のインデックスで情報の新しさが保たれるよう頻繁にクロールされる傾向があります。
- 古さ: Google のシステム側からは、変更の反映に十分な頻度でドキュメントを再クロールしたいと考えています。
引用:大規模なサイト所有者向けのクロールの割り当て管理ガイド | 検索セントラル | Google Developers
クローラーが通常よりも頻繁に訪れるWebサイトのクローラビリティは最高に高い状態です。
被リンク(外部リンク)の獲得
外部のWebサイトからリンク (被リンク)を獲得することで、クローラビリティを上げることができます。
前述のように、検索エンジンのクローラーはリンクからリンクへと移動をします。
外部サイトに自サイト(自分のWebサイト)のリンクが設置されることで、クローラーは自サイトへ移動しやすくなります。
ただし、被リンクの獲得は数が多ければクローラビリティが上がるものではありません。
Webページ同士の関連性が低いリンク、低品質コンテンツからの被リンク、お互いのWebページに被リンクを送る相互リンク、お金を払って被リンクを獲得する、などは検索エンジンからの評価を落とす原因になります。
被リンクを獲得するためには「高品質なコンテンツ」が求められます。
そして、検索エンジンから評価されるような被リンクが多いWebサイトは、当然多くのユーザーからも高い評価を受けています。
インターネット上で高い評価を受けているWebサイトは、常に最新の状態でインデックスされるべきだと検索エンジンに判断されている状態です。
そのため、評価を受けていないWebサイトに比べてクローラビリティが高い状態といえます。
クローラーが頻繁に訪れる、また被リンクを獲得するWebサイトになるためにも、高品質なコンテンツを作成しましょう。
重複ページのURLを正規化
重複ページのURLを正規化することで、クローラビリティが向上します。
重複コンテンツとは、以下のような複数のURLからアクセス可能なコンテンツのことです。
- 「www.」のありなし
- 「http://」「https://」
- 「/index.html」のありなし
- 「パソコン用」「スマートフォン用」で別のURL
重複コンテンツ同士の関係性を検索エンジンに伝えなければ、クローラーはそれぞれのURLを巡回しなければいけません。
また、重複コンテンツ同士の関係性を検索エンジンに伝えていない状態は、コピーコンテンツと判断され、ペナルティの対象となる可能性があるので注意が必要です。
重複コンテンツに該当するURLを正規化することで、検索エンジンにそれぞれの重複コンテンツの関係性が伝えられ、また無駄なクロールも減らせます。
301リダイレクトを設定し正規URLに転送することでも、以上のように関係性を伝える、またクロールを減らせるのでおすすめです。
よって、重複ページのURLを正規化することでクローラビリティが向上します。
関連記事
重複コンテンツについては、以下のコラム記事で詳しく解説しています。
・重複コンテンツのSEOへの影響と対処法について
URLの正規化については、以下のコラム記事で詳しく解説しています。
・URLの正規化とは?正規化するべき3つの理由と具体的な方法を徹底解説
Webサーバーの最適化
Webサーバーの最適化は、クローラビリティの向上につながります。
Webサーバーに負荷がかかると処理速度が遅くなり、最悪の場合には500エラーが生じてWebサイトにアクセスできない状態になる可能性があります。
Googleが運営するウェブマスター向け公式ブログでは、Webサイトの表示速度が遅いまたはサーバーエラーが返される場合、クロール速度の上限が下がりクローラビリティが低下すると述べられています。
クロールの状態: しばらくの間サイトが迅速に応答している場合、クロール速度の上限が上がり、クロール時に使用可能な接続の数が増えます。サイトの応答が遅くなった場合やサーバーエラーが返される場合、クロール速度の上限が下がり、Googlebot によるクロールが減ります。
Webサーバーを最適化させることで、Weページの表示速度が速くなったり、サーバーエラーが起きにくくなります。
結果的にクロール速度の上限が上がり、クローラビリティが向上するのです。
ファイルの最適化
Webサイト内にあるファイルを最適化することで、クローラビリティが向上します。
検索エンジンのクローラーは、Webページにある「画像」「CSS」「JavaScript」などのファイルもクロールします。
不要なファイルが多くあると、その分クローラーのリソースが増してしまうのです。
ファイルの最適化には不要ファイルの削除やファイルの圧縮、キャッシュの活用などが挙げられます。
ファイルが最適化されると、クローラーのリソースが減るだけでなく、Webサーバーの表示速度が速くなってクロール速度の上限が上がり、クローラビリティの向上ができるのです。
正しいHTTPステータスコードを返す
検索エンジンのクローラーに正しいHTTPステータスコードを返すことで、クローラビリティが向上します。
HTTPステータスコードとは、クライアント(利用者)のブラウザからのリクエストに対して、Webサーバーがレスポンスを返すときに表す3桁の数字のことです。
代表的なHTTPステータスコードは以下の通りです。
▼スマホの場合は横にスクロールしてご覧ください
| ステータスコード | 内容 |
|---|---|
| 200 | 正常なレスポンス |
| 301 | 恒久的(永久的)な転送 |
| 404 | レスポンスを返せない状態 |
クローラーは、HTTPステータスコードの状態を検索エンジンに伝えます。
仮に正しくHTTPステータスコードが返されない場合、検索エンジンにWebページの状態を誤認させる可能性があるため注意が必要です。
たとえば、あるWebページが「404 Not Found」で返されるべきときに「200 OK」が返されてしまうと、低品質なコンテンツと判断されるだけでなく、クローラビリティの低下にもつながります。
また、評価の低いユーザー体験が検索エンジンに伝わり、ユーザーエクスペリエンスに悪影響を及ぼしかねません。
その結果、検索エンジンに検出させたいWebページのアクセスが減少する可能性もあります。
このようなHTTPステータスコードのエラーは、Googleサーチコンソールの「カバレッジ」レポートで確認できます。
カバレッジレポートにエラーの原因が記載されるので、対策をしてクローラーに正しいHTTPステータスコードを返しクローラビリティを向上させましょう。
シンプルなURLを設定
クローラビリティを向上させるためにシンプルなURLの設定をおすすめします。
Googleも複雑なパラメータを含むURLがクロールのリソースを増やし、クローラビリティ低下の原因になると述べています。
特に複数のパラメータを含む URL など、過度に複雑な URL は、サイト上の同じまたは同様のコンテンツを表す多数の URL を不必要に作成し、クロールの際に問題が生じることがあります。その結果、Googlebot が必要以上に帯域幅を消耗してしまい、サイトのコンテンツをすべてインデックスに登録しきれない状態を招く可能性があります。
高品質のコンテンツがクロールされずにインデックスされない状況は、Webサイト全体のSEO評価に関わります。
URLはコンテンツの内容やカテゴリーを考慮して、可能な限りシンプルに設定することが大切です。
たとえば「友達に渡す誕生日プレゼント」という記事であれば、URLは「https//○○○.com/gift-your-friends」などシンプルにするといいでしょう。
特定のファイルにrobots.txtを設定
特定のファイルに「robots.txt」を設定することで、クローラビリティが向上します。
robots.txtとは、検索エンジンのクローラーにWebページをクロールされないように制御するファイルのことです。
前述しましたが、検索エンジンのクローラーはコンテンツファイルもクロールします。
そのため、重要性の低いコンテンツファイルへのクロールを拒否することがクローラビリティの向上には必要です。
たとえば「画像」「PDF」「Word(.doc/.docx)」などのファイルや、アクセス制限付きWebページや管理ページなどは重要度が低いといえます。
このようなファイルやWebページには、robots.txtを設定してクロール拒否しましょう。
しかし、robots.txtの設定には以下の注意が必要です。
- Webサイト全体に「robots.txt」を設定しない
- 「noindex」の設定が認識されない
Webサイト全体のクロールを拒否してしまうと、すべてのWebページが検索エンジンのデータベースに登録されずインデックスされなくなります。
また、設定ミスによってインデックスさせたいWebページがクロールされないこともあるので注意が必要です。
そして、robots.txtを設定すると「noindex」の設定が認識されなくなります。
たとえば、低品質コンテンツや重複コンテンツにnoindexタグを設定し、インデックスされないようにしているWebページがrobots.txtの設定によって検索結果に表示されるのです。
noindexを優先的に認識させたい場合は、robots.txtの設定を併用しないようにしましょう。
robots.txtやnoindexの設定によりクロールのリソースを減らし、クローラビリティの向上を目指しましょう。
不要なアクセスをブロック
不要なアクセスをブロックすることで、クローラビリティが向上します。
例えば、リファラースパムのようなアクセスが急増すると、サーバーに負荷がかかって処理速度が遅くなり、その結果クローラビリティが低下する可能性があります。
リファラースパムのような不要なアクセスをブロックすることで、クローラビリティの向上につながります。
ただし、アクセスをブロックする設定を誤ればWebサイトへのアクセスを失う可能性もあるので注意が必要です。
不要なアクセスをブロックするには、アクセス元のドメインやIPアドレスを拒否するコードを「.htaccess」ファイルに記述します。
.htaccessは、Webサーバーの動作をディレクトリ単位で制御できるファイルのことです。
アクセス元のドメインやIPアドレスは、Googleアナリティクスのリファラーやアクセスログから確認できます。
クローラーがWebサイトに訪れているか確認する方法
検索エンジンのクローラーがWebサイトに訪れているか確認する方法を2つ紹介します。
- 「site:」で確認する方法
- Googleサーチコンソールで確認する方法
以上の2つの確認方法についてくわしく見てみましょう。
「site:」でクローラーの訪問を確認する方法
「site:」でクローラーの訪問を確認する方法と注意点についてです。
「site:」での確認方法は、クローラーが訪問してインデックス登録したURLが検索結果上に表示されます。
出典:Google
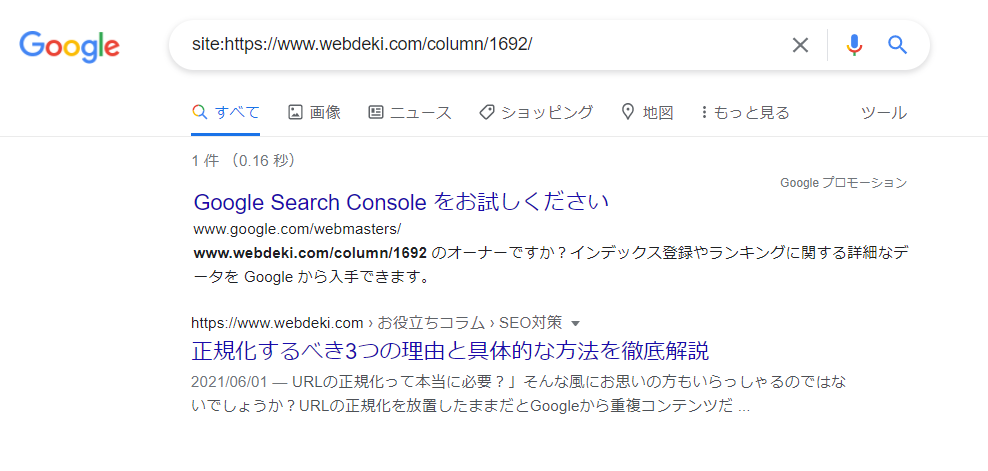
確認方法はブラウザの検索窓に「site:対象のURL」を入力して検索をするだけです。
そうすると、検索結果上にインデックス登録されているURLが表示されます。
確認したいWebページが検索結果に表示されていれば、クローラーが訪問しているということです。
ただし、本来「site:」による検索の目的は「サイト内検索」なので、クローラーの訪問を確認する方法として利用するのは不適切といえます。
クローラーの訪問を確認するには、後述する「Googleサーチコンソール」でおこないましょう。
Googleサーチコンソールでクローラーの訪問を確認する方法
Googleサーチコンソールでは、クローラーの訪問を確認することができます。
Googleサーチコンソールの「URL検査」ツールを使えば、クローラーが訪問して検索エンジンのデータベースにインデックス登録されているか確認できます。
「URLはGoogleに登録されています」と表示されていれば、問題なくクローラーが訪問している状態です。
しかし、そうでない場合は「インデックス登録をリクエスト」を選択することで、クローラーの巡回を依頼できます。
インデックス登録をリクエストしたにもかかわらず、インデックス登録されない場合は「カバレッジ」レポートを確認しましょう。
カバレッジレポートは以下の4つのステータスでインデックス状況を伝えます。
- エラー:インデックスされていないWebページ
- 有効(警告あり):インデックス登録済みだが注意点あり
- 有効:インデックス登録済みで問題ないWebページ
- 除外:エラー以外の原因でインデックスされていない
以下はカバレッジレポートの対応別の優先順位です。
▼スマホの場合は横にスクロールしてご覧ください
| ステータス | 対応別の優先順位 |
|---|---|
| エラー | ・高い クロールに失敗、インデックス登録されていないURL数 |
| 除外 | ・やや高い 「エラー」による原因以外でインデックスされていないURL数 |
| 有効(警告あり) | ・低い Webサイトに悪影響を及ぼす可能性は低い |
| 有効 | ・問題なし 問題なくインデックス登録されている状態 |
Googleサーチコンソールであれば正確にクロール状況を確認できます。
カバレッジレポートでは上記の表のステータスの他にも、クロール日時も確認できるので、いつクロールされたのか確認できます。
また、Googleサーチコンソールではクローラーの動きを確認することもできます。
Googleサーチコンソールの「設定」から「クロールの統計情報」のレポートを開くと、クロールの統計情報がみられます。
「クロールリクエストの合計数」「合計ダウンロードサイズ(バイト)」「平均応答時間(ミリ秒)」など、過去90日間のホストのステータスが表示されるので、Webサイト分析に役立つはずです。
さらに、クロールの統計情報では「レスポンス別」「目的別」「ファイル形式別」「Googlebotタイプ別」にクロールリクエストの詳細を確認できます。
クローラーの仕組みを理解しておけば不測の事態に対応ができるので、ぜひGoogleサーチコンソールでクローラーの動向をチェックする習慣を身につけましょう。
まとめ
今回は、Webサイトのクローラビリティを向上して上位表示するための改善ポイントを解説しました。
改めて、クローラビリティについておさらいしていきます。
- クローラビリティが向上しているWebサイトはSEO面で有利
- クローラビリティでSEO効果を得るにはコンテンツの質が大事
- 高品質なコンテンツを含むWebサイトは頻繁にクローラーが訪れる
- クローラーのリソースを減らすことでクローラビリティが向上する
- Googleサーチコンソールでクローラーの動きを確認できる
今回のコラム記事を参考にして、ご自身のWebサイトでクローラビリティの最適化を目指しましょう。





まずは無料でご相談ください。
お問い合わせ・ご相談や、公開後の修正依頼などに関しては、いずれかの方法にてお問い合わせください。
※年末年始・土日祝は定休日となります
※受付時間 9:00~17:30
